동시성(Concurrency)과 병렬성(Parallelism)
이 포스팅에서는 동시성과 병렬성의 의미적 차이와, 파이썬에서의 차이를 라이브러리와 함께 알아본다.
동시성(Concurrency)과 병렬성(Parallelism)
동시성과 병렬성은 CS공부를 하다보면 또는 업무를 하다보면 반드시 만나게 되는 단어다.
이러한 기법들은 순차적 (Sequential) 프로그래밍보다 더욱 어렵다는 단점이 있다.
작업의 결과가 비결정적이기 때문에 결과에 대한 예측이 어렵고, 디버깅 또한 쉽지 않다.
하지만 한번에 두개 이상의 작업에 대해 수행이 가능하다는 엄청난 장점(두배 이상 빠르다는것은 절대로 아니다) 때문에 반드시 알아두어야 하는 개념이다.
이제 실제 동작을 들여다 보자.
병렬성(Parallelism)
병렬 컴퓨팅 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 병렬 컴퓨팅(parallel computing) 또는 병렬 연산은 동시에 많은 계산을 하는 연산의 한 방법이다. 크고 복잡한 문제를 작게 나눠 동시에 병렬적으로 해결하는 데에
ko.wikipedia.org
CS에서 말하는 병렬성이란 실제로(물리적으로) 동시에 두개 이상의 작업들이 수행되는것을 의미한다.

작업들이 물리적으로 동시에 수행되므로 작업에 소요되는 시간은 배로 줄어들게 되고, 작업에 소요되는 자원은 배로 늘어나게 된다.
이러한 병렬 컴퓨팅의 예시로는 GPU 작업이 있다. GPU의 경우 작은 처리 유닛이 아주 많이 존재하고, 이러한 처리 유닛들이 병렬적으로 (물리적으로 동일한 시간에 여러개의 작업을 동시에) 작업을 처리하므로, 행렬 계산등에 유리하다.
동시성 (Concurrnecy)
Concurrent computing - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Executing several computations during overlapping time periods Concurrent computing is a form of computing in which several computations are executed concurrently—during overlapping
en.wikipedia.org
CS에서 말하는 동시성이란 작업들이 실제로(물리적으로) 동시에 수행되진 않지만, 아주 빠른 시간동안 두개 이상의 작업을 번갈아가며 수행해 동시에 여러 작업들을 수행하는 컴퓨터 패러다임중 하나다.
아래 그림은 두개의 작업이 빠르게 교대되어 실행되는 모습을 보여준다.
빠른 시간동안 두 작업이 번갈아 가며 실행되기 때문에 마치 두개의 작업이 동시에 수행되는것처럼 느껴지게 한다.

이러한 작업은 결국 한 시점에는 하나의 작업만 수행할수 있고, 작업이 번갈아 수행되기에 소요되는 비용(Context Switching) 때문에 오히려 순차적(Sequential) 작업보다 능률이 나오지 않을 수 있다. 때문에 Cpu Bound 작업과 I/O Bound작업을 적절하게 배치하고, 각 잡업의 특성을 이해하고 배치하는 프로그래머의 노력이 필요하다.
파이썬에서의 Parallelism 작업
파이썬에는 GIL이라는 락이 존재하여 프로세스내에 아무리 많은 스레드를 만들어도 결국 한번에 하나의 스레드만 작업을 수행할 수 있다.
때문에 파이썬에서 병렬 작업을 수행하기 위해선 프로세스를 늘리는 멀티 프로세스를 사용하여 작업을 수행한다.
다음 수행에 약 1초 (0.8~0.9초) 정도 걸리는 단순한 작업이 있다.
import time
import os
def task1():
sys.stdout.write("작업 시작\n")
a = 0
for i in range(30000000):
a += 1
sys.stdout.write("작업 완료\n")
if __name__ == "__main__":
print("main pid : ", os.getpid())
st = time.time()
task1()
et = time.time()
print("실행시간 : ", et - st)
이제 파이썬에서 멀티프로세스를 다루는 방법에 대해 알아보자.
파이썬에서 멀티 프로세스 작업을 하기위한 라이브러리로는 multiprocessing 라이브러리가 있다.
multiprocessing — Process-based parallelism — Python 3.10.7 documentation
Source code: Lib/multiprocessing/ Introduction multiprocessing is a package that supports spawning processes using an API similar to the threading module. The multiprocessing package offers both local and remote concurrency, effectively side-stepping the G
docs.python.org
이 포스팅은 해당 라이브러리의 사용법에 대한 포스팅이 아니므로 사용법은 굳이 언급하지 않는다.
해당 라이브러리에는 프로세스풀을 생성하는 Pool이라는 클래스가 존재한다.
아래는 해당 클래스를 사용하여 프로세스풀을 생성하고, 해당 프로세스풀에 작업을 할당하는 예시다.
import time
import os
import sys
from multiprocessing.pool import ThreadPool, Pool
def task1():
sys.stdout.write("작업 시작\n")
a = 0
for i in range(30000000):
a += 1
sys.stdout.write("작업 완료\n")
if __name__ == "__main__":
print("main pid : ", os.getpid())
st = time.time()
pool = Pool(processes=5) # 프로세스풀에 5개의 프로세스 생성
for i in range(5):
pool.apply_async(task1) # 작업을 비동기로 할당하기 위해 appyl가 아닌 apply_async 사용
pool.close() # 더이상 프로세스풀을 사용하지 않고 종료합니다.
pool.join() # 프로세스가 끝날때까지 기다립니다.
et = time.time()
print("실행시간 : ", et - st)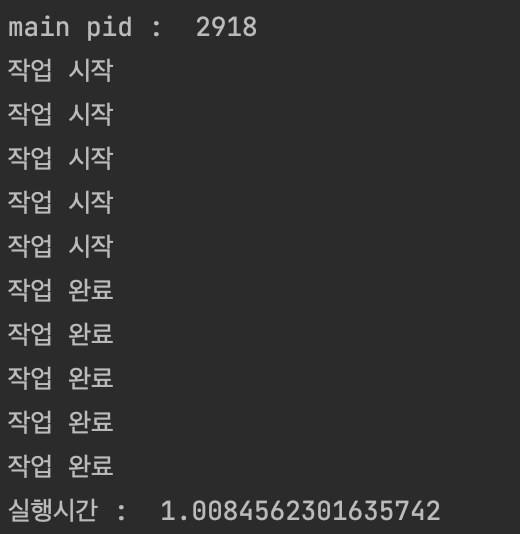
위 예제에서는 프로세스풀에 프로세스를 5개 생성하고, 해당 프로세스에 5개의 작업을 할당하는 예제다.
1초씩 걸리는 작업 5개가 할당되었지만 5초가 걸리지 않고, 병렬적으로 작업이 수행되어 약 1초정도 걸리게 된다.
프로세서들(실제 코어들)이 1초동안 해당 작업만 수행하는것은 아니므로 하나의 작업이 끝나는데 걸리는 시간보다는 조금 더 걸리게 된다. (context switching)
작업이 병렬적으로 수행될경우, 작업의 효율은 배로 올라가는것을 볼 수 있다.
파이썬에서의 Concurrency 작업
파이썬에서 동시성 작업을 위한 방법은 여러가지가 있다.
이번 포스팅에서는 그중에서 스레드를 사용하는 방법에 대해 알아본다.
파이썬은 GIL때문에 하나의 프로세스에서는 동시에 하나의 스레드만 수행이 가능하다.
때문에 여러개의 N개의 스레드를 만들더라도 작업이 수행되는데에는 N배의 시간이 걸리게 된다.
이러한 스레드를 다루기 위한 방법은 threading이라는 모듈과, multiprocessing.pool.ThreadPool이 있다.
이번 예제에서는 스레드 풀에대해서만 다룬다.
아래 예제는 위의 병렬 작업과 동일한 작업(1초 걸리는 task1)을 동일한 조건에서 5번 실행해 보는 예제다.
import time
import os
import sys
from multiprocessing.pool import ThreadPool, Pool
def task1():
sys.stdout.write("작업 시작\n")
a = 0
for i in range(30000000):
a += 1
sys.stdout.write("작업 완료\n")
if __name__ == "__main__":
print("main pid : ", os.getpid())
st = time.time()
tpool = ThreadPool(5)
for i in range(5):
tpool.apply_async(task1)
tpool.close()
tpool.join()
et = time.time()
print("실행시간 : ", et - st)
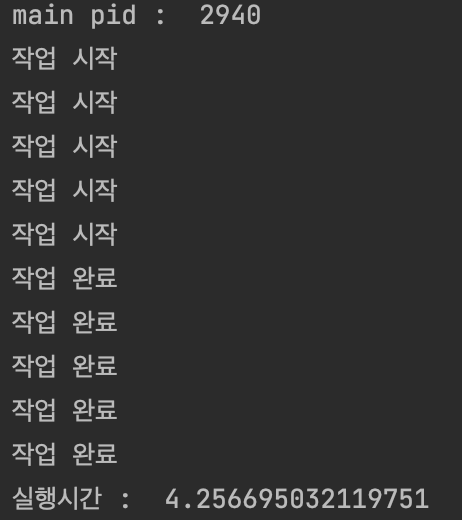
두 예제 모두 5개의 스레드에 작업을 주고 모든 스레드가 작업을 수행할때까지 기다리는 예제다.
동일한 작업을 수행했지만, 프로세스를 만들어 병렬적으로 처리한 경우에는 약 1초정도로 작업 하나의 수행과 별반 다르지 않은 수행시간을 보였지만, concurrency하게 수행된 경우에는 약 4~5배정도의 시간이 걸린것을 알 수 있다.
효율적인 동시성 프로그래밍
개발자는 동시성 프로그래밍의 효율에 대해 끊임없이 고민해야 한다.
동시성 프로그래밍은 결국 작업을 수행하는 주체(코어) 가 결국 하나의 작업을 수행할 수 밖에 없다.
이러한 특성을 알고 개발자는 작업의 특성을 파악하고 적절하게 작업을 분배해야 한다.
예를들어 CPU Bound 작업들의 경우는 아무리 동시성 프로그래밍을 통해 수행한다 해도, 시간적 이득을 얻기 힘들다.
하지만 I/O Bound 작업의 경우는 얘기가 달라진다.
아래는 I/O Bound의 동시성 프로그래밍을 위한 예시에 사용될 서버 코드다.
server.py
from flask import Flask
import time
import os
app = Flask(__name__)
@app.route('/test')
def test():
time.sleep(1)
return "hello world!"
app.run()
요청이 들어오면 약 1초간의 sleep 이후 리턴해주는 예시다.
아래는 해당 서버에 요청을 보내고 결과를 받는 예시다.
client.py
import os
import requests
import sys
def task2():
sys.stdout.write("작업 시작\n")
res = requests.get('http://localhost:5000/test')
sys.stdout.write(f'{res.text}\n')
sys.stdout.write("작업 완료\n")
if __name__ == "__main__":
print("main pid : ", os.getpid())
st = time.time()
task2()
et = time.time()
print("실행시간 : ", et - st)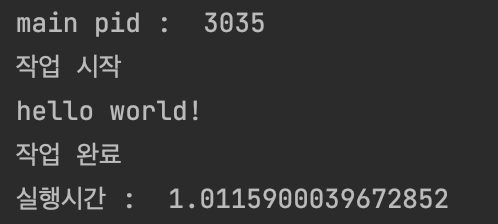
위 task2를 동시성 프로그래밍의 예시에서 사용된 코드 그대로 5개의 스레드 풀을 만들어 수행해 보았다.
import os
import requests
import sys
def task2():
sys.stdout.write("작업 시작\n")
res = requests.get('http://localhost:5000/test')
sys.stdout.write(f'{res.text}\n')
sys.stdout.write("작업 완료\n")
if __name__ == "__main__":
print("main pid : ", os.getpid())
st = time.time()
threads = []
for i in range(5):
t = threading.Thread(target=task1)
t.start()
threads.append(t)
for t in threads:
t.join()
et = time.time()
print("실행시간 : ", et - st)

이번에도 역시 1초동안 걸리는 작업(task2)를 concurrency하게 5번 수행하였지만, 총 수행결과는 1초밖에 걸리지 않았다.
이것이 개발자가 작업의 특성을 이해하고, 적절한 배치를 통해 효율성을 높여야 하는 이유다.
동일하게 수행에 1초가 걸리는 작업(task1, task2) 이지만, 작업의 특성 (Cpu Bound, I/O Bound)에 따라서 수행되는 시간이 달라지게 되는것이다.
결론
동시성 : 작업이 동시에 수행되는것 (좁은의미로는 작업이 아주 작은 시간동안 번갈아가며 수행되는것), 논리적 의미
병렬성 : 작업이 물리적으로 동시에 수행되는것, 물리적 의미
동시성 프로그래밍의 경우 작업의 특성에 따라 어떻게 배치하냐에 따라 프로그램의 효율성이 달라지게 된다.